數據治理體系規劃設計方案——數據處理與存儲服務專題
數據治理體系規劃設計方案
第五部分:數據處理與存儲服務
一、 引言與目標
在數字化轉型浪潮下,數據已成為組織的核心戰略資產。本方案旨在構建一個統一、高效、安全、可擴展的數據處理與存儲服務體系,作為整個數據治理體系的堅實技術底座。其核心目標是:
- 標準化處理:規范數據從接入到應用的全流程處理,確保數據質量與一致性。
- 彈性化存儲:根據數據價值、訪問頻率與合規要求,設計分層分域的存儲架構,實現成本與性能的最優平衡。
- 服務化供給:將數據處理與存儲能力封裝成可復用的服務,提升業務部門的數據獲取與分析效率。
- 安全可控:貫穿全生命周期的數據安全與隱私保護策略,滿足法律法規要求。
二、 核心架構設計
我們的數據處理與存儲服務體系采用分層解耦、服務導向的架構,主要包括以下四層:
1. 數據源與接入層
- 多源異構接入:支持從業務數據庫、日志文件、IoT設備、第三方API等各類數據源的實時與批量數據采集。
- 統一接入規范:制定數據接入標準協議與格式,確保數據入口的規范與質量。
- 關鍵組件:ETL/ELT工具、消息隊列(如Kafka)、數據同步平臺。
2. 數據處理與計算層
- 批流一體處理:集成批處理(如Spark, Hive)與流處理(如Flink, Storm)引擎,滿足不同時效性要求的數據加工需求。
- 數據處理流水線:通過可視化或代碼方式編排數據處理任務,實現數據清洗、轉換、聚合、關聯的自動化。
- 統一計算資源調度:采用YARN或Kubernetes進行資源管理與隔離,提升集群利用率。
3. 數據存儲與管理層(核心)
這是規劃的重點,我們設計“三層六域”的存儲體系:
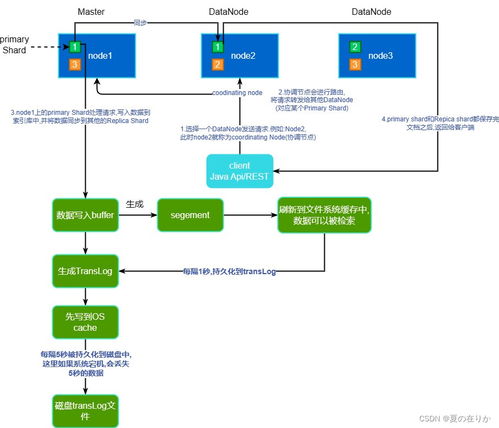
- 原始數據層(ODS):
- 存儲域:數據湖(如HDFS, S3兼容存儲)。
- 定位:存儲全量、原始的、未經加工的源數據副本,保留最大粒度信息,用于回溯與探索分析。
- 通用數據層(CDM):
- 明細數據域(DWD):數倉(如Hive, ClickHouse)、MPP數據庫。對原始數據進行清洗、標準化、維度退化后形成的業務過程明細數據。
- 聚合數據域(DWS):同一數倉或分析型數據庫。基于明細數據,按主題域或業務維度進行輕度匯總的公共匯總層。
- 維度數據域(DIM):關系型數據庫或數倉。存儲一致性維度表,確保業務口徑統一。
- 應用數據層(ADS):
- 個性化數據域:多樣化存儲(如ES, Redis, MySQL,圖數據庫)。為滿足特定報表、應用接口(API)、數據產品、AI模型訓練等需求而構建的個性化數據集合。
- 歸檔/冷數據域:對象存儲或磁帶庫。用于存儲訪問頻率極低但需長期保留的數據,成本最優。
4. 數據服務與API層
- 統一數據服務網關:提供統一的API訪問入口,進行認證、鑒權、限流與監控。
- 多樣化數據服務:提供即席查詢、固定報表、數據訂閱、實時推送、模型評分等多種服務模式。
- 元數據與數據目錄服務:提供數據的“地圖”與“說明書”,讓用戶能夠快速查找、理解和使用數據。
三、 關鍵服務流程
- 數據入湖入庫流程:定義從數據接入、格式校驗、基礎清洗到存入數據湖或ODS的標準流程。
- 數據加工與建模流程:基于數據建模成果(維度模型、數據主題域),通過ETL/ELT任務將數據從ODS層逐層加工至CDM層。
- 數據服務化流程:業務方通過數據目錄查找數據,申請訪問權限,數據團隊將CDM層數據或加工后的ADS層數據,通過API、數據文件、數據庫賬號等方式安全交付。
- 數據歸檔與銷毀流程:根據數據生命周期策略,自動將到期冷數據遷移至歸檔域,對超過保留期限或無價值的數據執行安全銷毀。
四、 技術選型建議
- 大數據基礎平臺:建議采用云原生大數據平臺(如阿里云DataWorks+MaxCompute+DataHub,或AWS EMR+Glue+S3)或基于CDH/TDH的混合云方案。
- 核心存儲引擎:
- 數據湖存儲:HDFS / 對象存儲(S3/OSS/OBS)。
- 數倉與分析引擎:Hive / Spark SQL / ClickHouse / Doris。
- 關系型與事務型:MySQL / PostgreSQL / TiDB。
- 緩存與檢索:Redis / Elasticsearch。
- 數據處理與調度:Airflow / DolphinScheduler / 云廠商數據開發工具。
- 數據服務與API管理:API網關(如Kong, Apigee)與自研數據服務中間件。
五、 實施路線圖(建議)
- 第一階段(1-3個月):基礎平臺搭建與試點
- 完成大數據基礎環境部署。
- 建立核心數據源接入通道與原始數據湖。
- 選擇1-2個關鍵業務主題,完成端到端的數據處理與服務化試點。
- 第二階段(4-9個月):核心體系擴展
- 擴展數據接入范圍,覆蓋主要業務系統。
- 構建企業級數據倉庫(CDM層)的核心主題域模型。
- 建立初步的數據服務目錄與API發布能力。
- 第三階段(10-18個月):服務深化與運營
- 完善分層存儲體系,實施數據生命周期管理。
- 深化數據服務能力,支持自助分析與實時數據服務。
- 建立穩定的數據運維體系與持續優化機制。
六、
數據處理與存儲服務是數據價值實現的“生產車間”與“倉庫”。本規劃通過清晰的架構分層、嚴謹的存儲域劃分、標準化的處理流程和服務化的交付模式,旨在構建一個靈活、健壯、高效的數據基礎設施,為上層的數據分析、智能應用與業務創新提供源源不斷的可靠“數據燃料”,最終驅動企業數字化轉型的成功。
---
附錄:本方案需與《數據標準管理》、《數據質量管控》、《數據安全策略》等專題方案協同實施。
如若轉載,請注明出處:http://www.evidawinds.cn/product/43.html
更新時間:2026-04-14 08:59:50